Tutorial 4
Question 1 - What is Apache spark? why spark has come into existence? brief architecture of Apache Spark
Answer 1 - Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Major issues with Apache Hadoop.
1. Issue with Small Files
2. It has Slow Processing Speed
3. Only support for Batch Processing only
4. There is no support for Real-time Data Processing
2. It has Slow Processing Speed
3. Only support for Batch Processing only
4. There is no support for Real-time Data Processing
To overcome all these issues, Apache Spark comes into the picture. one more reason behind Evolution of Apache Spark is that there were many general purpose computing engines those can perform operations but again they attain some limitations with their functionality itself.
For Example:
1. Hadoop MapReduce is limited to batch processing.
2. Apache Storm / S4 can only support stream processing.
3. Apache Impala / Apache Tez can only allow interactive processing
4. Neo4j / Apache Giraph can only support graph processing
1. Hadoop MapReduce is limited to batch processing.
2. Apache Storm / S4 can only support stream processing.
3. Apache Impala / Apache Tez can only allow interactive processing
4. Neo4j / Apache Giraph can only support graph processing
Therefore, If we want to use them together, reduces the efficiency and also increases the complexity. So, there is a big demand for a powerful engine. By that, we can process the data in real-time (streaming) as well as in batch mode.
Components of Spark
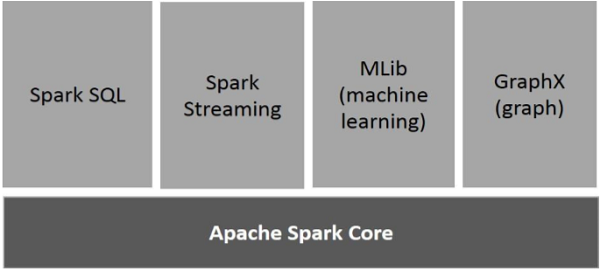
Apache Spark Core
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems.
Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data.
Spark Streaming
Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
MLlib (Machine Learning Library)
MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It is, according to benchmarks, done by the MLlib developers against the Alternating Least Squares (ALS) implementations. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
GraphX
GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
Question 2 - What is Spark SQL and what is the use of data frames in spark?
Answer 2 - Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations. There are several ways to interact with Spark SQL including SQL and the Dataset API. When computing a result the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between different APIs based on which provides the most natural way to express a given transformation.
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of
Reference : https://spark.apache.org/Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row].

Comments
Post a Comment